About NetPulse AI
NetPulse AI is a multi-agent telecom operations assistant built for the APAC GenAI Academy 2026 hackathon. A natural-language complaint goes in; a structured incident ticket comes out — complete with the related network events the operator should know about, the CDR findings that back up the customer’s account of what happened, and a recommended NOC action plan.
Architecture in detail
The core ADK package telecom_ops exposes a
SequentialAgent that runs four LlmAgent sub-agents
in order: classifier, network investigator, CDR analyzer, response
formatter. Each one reads the shared session state, queries its data
store through the MCP toolbox, and enriches the state for the next.
The fourth writes a structured ticket to AlloyDB and the run ends.
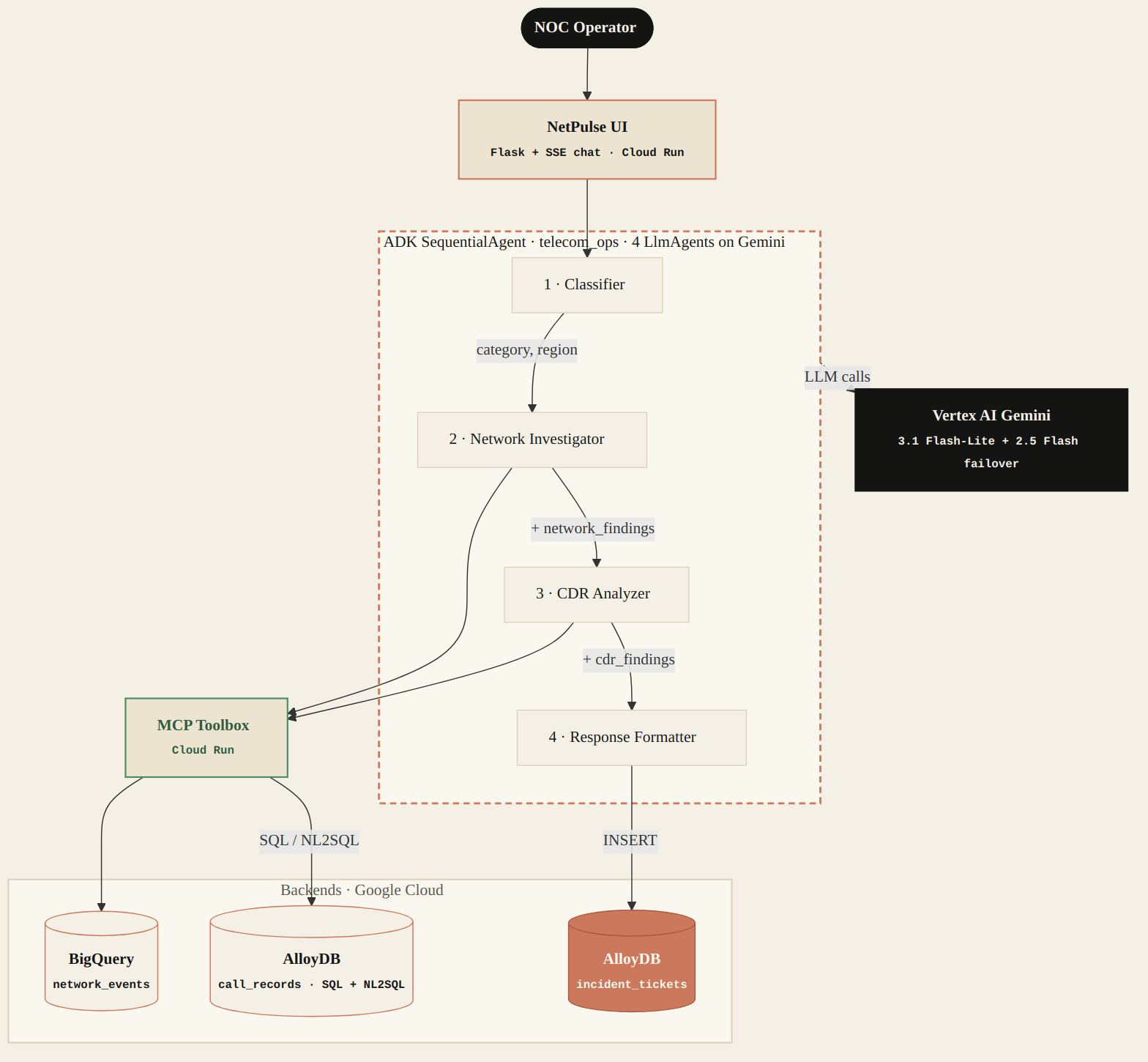
Why a SequentialAgent
The four steps have strict data dependencies — the network
investigator can’t run until the classifier has tagged a region; the CDR
analyzer joins on the time window the network investigator returned;
the formatter needs all three to write a coherent ticket. A
SequentialAgent models this as code rather than encoding it
into a prompt, so the dependency stays correct under prompt churn.
Why MCP Toolbox in front of the data stores
Direct BigQuery MCP endpoints returned 403 / connection-closed on Cloud Run during early integration. The toolbox-as-intermediary pattern works reliably and gives one place to evolve tool definitions without redeploying the agent service.
Why both BigQuery and AlloyDB
All-BigQuery makes ticket writes/updates painful — no transactions, latency wrong for an interactive UI. All-AlloyDB makes event scans expensive, forces scaling decisions for telemetry that doesn’t need a relational store, and loses the cheap historical depth. Showing two services used for the right reasons mirrors how telecom ops actually splits analytical investigation from operational record-keeping.
- Network telemetry is the textbook OLAP case — high-volume, append-only, bursty queries that scan wide time windows. Columnar storage + pay-per-query economics fit the “investigate the last N hours” pattern better than keeping AlloyDB hot enough to scan that volume.
- Serverless — no scaling decisions during the hackathon.
- Schema flexibility for evolving event shapes; new event types appear all the time in real telco data.
- Investigation queries are read-only, so BigQuery’s eventual-consistency / batch-load model is fine.
- CDR lookups are targeted — specific MSISDN, narrow time window, joinable with subscriber metadata. That’s point/range access on indexes, OLTP shape, not scans.
- Tickets need real ACID + frequent state transitions (
open → investigating → resolved). BigQuery is the wrong tool for mutable rows. - PostgreSQL compatibility gives rich SQL, foreign keys, and clean joins between CDRs and ticket records.
- Low-latency reads to power the Call Records and Incident Tickets viewer tabs without query-cost anxiety per page load.
Tech stack on Google Cloud
The complete list of moving parts. Everything is Google Cloud (the hackathon track requires it); the LLM-side work is Vertex AI Gemini.
output_key handoffs.gemini-3.1-flash-lite-preview at the global endpoint, with a 4-attempt model ladder failing over via gemini-3-flash-preview to gemini-2.5-flash under quota pressure.network_events table — DAY-partitioned on started_at, clustered by (region, severity). 50,000 events across 10 metros, 6-month rolling window.call_records served in two tiers: parameterized SQL primary (query_cdr_summary, query_cdr_worst_towers) executes in <2s; query_cdr_nl is the AlloyDB AI NL2SQL fallback for off-script free-form prompts. A structurally read-only role executes either path.incident_tickets — append-only writes via the native ADK tool save_incident_ticket. Connection pool refreshed every 5 minutes to dodge silent-death sockets.telecom_network_toolset) plus three CDR tools on AlloyDB (cdr_toolset: 2 parameterized SQL + 1 NL2SQL fallback) live in a separate Cloud Run service. Agents reach the data via the toolbox; the toolbox reaches the warehouses via service accounts.netpulse-ui wraps the same root_agent in a hero landing + workspace timeline. Each request runs its own asyncio loop in a worker thread; events stream out incrementally via Server-Sent Events.netpulse-ui serves the chat surface; network-toolbox hosts the MCP toolbox. Both built from a Dockerfile in the project root, deployed from main.Data schema three surfaces
Three data surfaces feed the run. Each viewer page describes its schema and filter dimensions in detail.
Bring your own data in three steps
NetPulse AI ships with seed data for ten Indonesian metros. Adapting to a different telecom dataset is a three-step exercise:
- Replace the seed CSVs in
docs/seed-data/with your ownnetwork_events.csvandcall_records.csv. Keep the column shapes intact — see network events schema and call records schema for column-by-column descriptions. - Re-run
scripts/setup_bigquery.py --seed --recreateto drop and rebuild the BQ table with your data, thenscripts/setup_alloydb.py --seedto load CDRs into AlloyDB. The--recreateflag is destructive but is the only way to reapply the partition + cluster spec. - Adjust the region whitelist in
telecom_ops/tools.py(VALID_REGIONS) and the toolbox config intools.yamlif your cities diverge from the Indonesian-metro defaults. The agents will pick up the new vocabulary on next deploy.
The agents themselves are dataset-agnostic — what changes is the
data, the region whitelist, and the natural-language prompt examples in
tools.yaml that ground AlloyDB AI’s NL-to-SQL translation.
Phase history over time
NetPulse AI was built through a series of timeboxed phases. Each phase landed in a single PR (in most cases) and was visually verified end-to-end before the next began.
- April 29, 2026EngineeringPhase 12 — Vertex model-ladder failover replaces region ladder→
- April 28, 2026ArchitecturePhase 11 — AlloyDB AI NL2SQL replaces hand-written CDR SQL→
- April 27, 2026RefactorPhase 10 — MCP toolbox refactor 8 tools → 2 universal tools→
- April 26, 2026EngineeringPhase 9 — Flash-Lite collapse + observer pill model unification→
- April 25, 2026ShipPhase 8 — Single consolidated Cloud Run redeploy→
- April 24, 2026FoundationPhases 1–7 — Refinement runway: audit → tokens → region failover → visual redesign → UX fixes → reproducibility → story polish→
- April 23, 2026MilestoneTop 100 — APAC GenAI Academy 2026 selection→
Roadmap next
The hackathon scope is a refined prototype, not a product. These are the next directions if the project continues past 2026-04-30.